论文链接:[2309.14030] DeWave: Discrete EEG Waves Encoding for Brain Dynamics to Text Translation
零基础引入
该论文提出了一个把脑电图(EEG)电信号直接翻译成文字的新范式,这一翻译的任务被称为“EEG to Text”。
研究背景
在DeWave面世之前,传统的EEG to Text范式都面临三个局限:
- 离不开眼动仪。所有的传统范式都需要受试者在阅读时佩戴眼动仪,这样才能根据受试者的眼动信息来为EEG信号“切段”,使得每一段信号对应一个字/词,依此为数据提供标签。但是这存在几处限制:第一,读者大脑中阅读的信息和眼睛正注视的内容不一定实时匹配;第二,眼动仪的捆绑造成了很大的不便;第三,有些特殊群体(如渐冻症患者)甚至无法佩戴眼动仪。
- 跨被试能力极差。对于同一个单词,不同的受试者在阅读时,大脑的神经活动差异巨大,因此就算模型在某一个受试者身上能较好地实现“EEG to Text”任务,但只要换另一个人来,效果就会急转直下。因此训练成本极高,完全谈不上普及。
- 无法翻译完整的语义。传统范式的学习目标还是一段EEG信号对应一个单词(标签),因此工作时还是只能一个词一个词地进行翻译,无法将单词连贯成句子。
本论文核心思路
先做一本通用的 “脑电普通话字典”(即论文中的离散码本 / Discrete Codex),字典里有几千个固定的 “标准词条”,所有词条都是统一的、无口音的 “普通话”。 不管你输入的是哪个人的、多长的连续脑电 “方言”,都先转换成这本字典里的 “普通话词条序列”。 最后,再把这个统一的 “普通话序列”,翻译成通顺的文字。
模型拆解
Step1. 把脑电信号转换成 “可处理的数字序列”(EEG 向量化)
我们采集到的原始脑电,是一堆连续的、波动的电信号,就像一段 raw 的录音,电脑没法直接处理,所以第一步要把它转换成电脑能看懂的、固定格式的数字序列(即论文中的「嵌入 / Embedding」)。
论文里分了两种情况,对应两种处理方式:
- 和之前的方法公平对比,用带眼动标记的词级脑电。就是按眼动仪的记录,把脑电切成对应每个字的片段,再提取每个片段的特征,转成固定长度的数字序列。
- 论文的核心创新,无任何标记的原始连续脑电。这里论文用了一个叫「Conformer」的结构,它能把一整段连续的脑电,切成一小段一小段的数字序列,每一段对应大概 200ms 的脑电(刚好是人脑处理一个单词的时间),不用任何眼动标记,完全自动处理。
Step2. 把 “脑电方言” 转换成 “普通话序列”(离散码本编码)
这一步是整个模型的核心,也就是「查普通话字典」的过程。
- 作者先做好了一本字典(离散码本),里面有 2048 个标准的 “普通话词条”(即论文中的「码本向量」),每个词条都是一个固定的数字序列。
- 上一步得到的脑电数字序列,每一段都去字典里找,和哪个词条最像,就用这个词条来代表这段脑电。
- 最后,一整段脑电,就变成了一串由字典里的词条组成的 “普通话序列”(离散编码)。
在生成离散码本时,论文用了两个关键方法:
- 自重建(自己编自己解):就像你把一句话转成拼音,再用拼音还原回原来的话,看看对不对。这里就是,把脑电转成字典里的编码,再用编码还原回原来的脑电信号。如果还原得很像,说明这个编码没有丢掉脑电的核心信息,是靠谱的。该方法实现了不用任何文字标注,只用脑电本身就能训练,完美解决了脑电数据少的问题。
- 文本对齐(让编码和文字意思对上):光还原脑电还不够,得让编码带上文字的意思。比如,脑子里想 “苹果” 的脑电,转成的编码,要和 “苹果” 这两个字的意思贴得很近,和 “香蕉” 的意思离得很远。论文用了一个叫「对比学习」的方法,该方法能让模型学会,对应同一句话的脑电编码和文字,要 “凑在一起”;不是同一句话的,要 “离远点”。这样一来,编码就不光是脑电的代表,还带上了语义,后面翻译就简单了。
Step3. 把 “普通话序列” 翻译成通顺的文字(预训练语言模型)
这一步,论文用了一个现成的预训练语言模型「BART」。
脑电 – 文字配对的数据集特别少,如同学翻译,只有几百句对照的句子,根本学不会怎么说通顺的话。但 BART 这种预训练语言模型,已经看过了互联网上几乎所有的英文书,早就学会了 “怎么说通顺的话”“怎么把一串意思翻译成完整的句子”。
所以 DeWave 根本不用让模型从头学 “怎么说话”,只需要让模型学会「这本普通话字典里的词条,对应什么意思」,然后直接用 BART 把普通话序列,翻译成通顺的文字。这就大大降低了训练难度,还让翻译出来的句子更通顺。
Step4. 两阶段训练,让模型效果越来越好
论文把训练分成了两步,如同学外语的过程,非常符合逻辑:
- 先把 “普通话字典” 练靠谱:先冻结翻译用的 BART 模型,只训练脑电编码器和字典,让字典能把各种脑电方言,都转换成靠谱的、带语义的普通话序列。就像先把拼音学标准了,再学翻译。
- 端到端微调,让翻译更准:把整个系统(脑电编码器、字典、BART 翻译模型)连起来,一起训练优化,让翻译出来的句子,和原本想表达的意思越来越像。就像拼音学完了,再对着双语句子练翻译,让翻译更精准。
深入模型实现
DeWave 整体架构总览
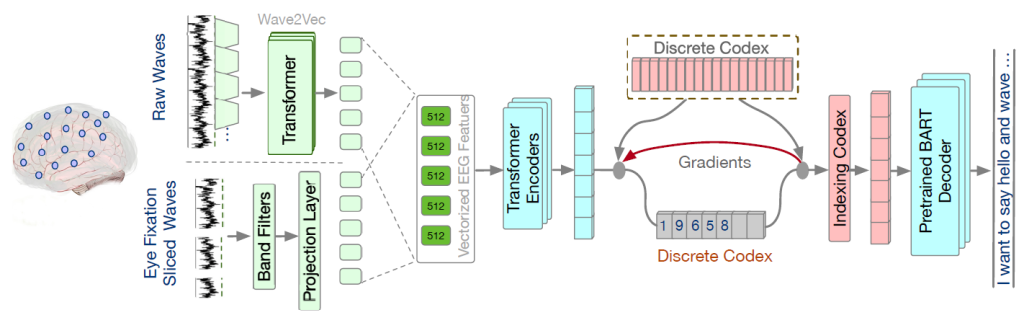
DeWave 是一个端到端的序列到序列(Seq2Seq)模型,核心设计思想是 “先统一表示,再语义翻译“—— 先将异构、高噪声、个体差异大的 EEG 信号,转换为统一、稳定、语义对齐的离散表示,再利用预训练大语言模型完成文本生成。
整个模型的数据流可以用一句话概括:原始 EEG 信号 → 向量化模块 → 连续隐表示 → 离散码本量化 → 离散语义序列 → 预训练 BART 解码器 → 自然语言文本