模糊的概念
现实中的许多现象及关系比较模糊。如高与矮, 长与短,大与小,多与少,穷与富,好与差,年轻与年老等。这类现象不满足 “非此即彼” 的排中律,而具有 “亦此亦彼” 的模糊性。需要指出的是,模糊不确定不同于随机不确定。随机不确定是因果律破损造成的不确定,而模糊不确定是由于排中律破损造成的不确定。
模糊集合的基本概念
传统集合的概念
传统集合是指具有相同属性的事物的集体,如正整数集合,具有如下性质:
- 互异性:集合中任意两个元素都是不同的对象,如[math]\{1 1 2\}[/math]和[math]\{1 2\}[/math]这两个集合是等价的;
- 逻辑性:每一个对象都能确定是不是某一集合的元素,这个性质主要用于判断一个集合是否能形成集合;
- 独立性:集合的基数、集合本身的个数必须为自然数;
- 无序性:[math]\{a b c\}[/math]和[math]\{c b a\}[/math]是同一个集合;
- 纯粹性:所谓集合的纯粹性,用个例子来表示,集合[math]A = \{x|x < 2\}[/math],集合A中所有的元素都要符合[math] x < 2 [/math];
- 完备性:仍用上面的例子,所有符合[math] x < 2 [/math]的数都在集合A中。
传统集合的特征函数
定义[math]U[/math]为论域,[math]f_A[/math]是[math]A[/math]集合的特征函数,有:[math] f_A:U \to \{0, 1\}[/math]
所谓论域可简单理解为我们要研究的集合,上面公式意义是将[math]U[/math]这个论域映射到[math]\{0, 1\}[/math]这个集合内,这里的冒号可理解成“作用于”的意思。
例如:及格集合[math]A = \{60, 61, 62, \dots, 100\}[/math],[math]f_A = \begin{cases} 1, & \text{成绩} \geq 60 \\ 0, & \text{成绩} \lt 60 \end{cases}[/math],
全班成绩集合[math]U = \{78, 97, 43, \dots, 59\}[/math]则可以表示为:[math]f_A(x) = \begin{cases} 1, & x \in A \\ 0, & x \notin A \end{cases}, \forall x \in U[/math],即将[math]U[/math]这个集合按照[math]f_A[/math]的特征,映射成了一个新的[math]\{0, 1\}[/math]集合。
模糊集合的隶属函数
定义[math]U[/math]为论域,[math]\mu_A [/math] 是 [math] A [/math] 集合的特征函数,有:[math]\mu_A:U \to [0, 1][/math](注意这里是闭区间)
这里的 [math] A = \text {“年轻”}[/math],[math] U = (0, 120)[/math]
定义隶属函数:
[math]\mu_A = \begin{cases}
1, & 0 < x < 20 \\
\dfrac{40 – x}{20}, & 20 \leq x \leq 40 \\
0, & 40 < x < 120
\end{cases}[/math]
对于 [math] U [/math] 中的每一个元素,均对应于 [math] A [/math] 中的一个隶属度,隶属度介于 [math][0, 1][/math],越大表示越属于这个集合。
模糊集合的表示方法
对于论域 [math] U = \{x_1, x_2, \ldots, x_n\}[/math],模糊集合为 [math] A [/math],隶属度为[math] A (x_i) \ (i = 1, 2, \ldots, n)[/math]
- 扎德表示法:[math] A = \frac {A (x_1)}{x_1} + \frac {A (x_2)}{x_2} + \ldots + \frac {A (x_n)}{x_n}[/math](注:这里的 [math]+[/math] 号并非是相加的意思,而仅仅表示记法);
- 序偶表示法:[math]\{(x_1, A(x_1)), (x_2, A(x_2)), \ldots, (x_n, A(x_n))\}[/math];
- 向量表示法:[math] A = \{A (x_1), A (x_2), \ldots, A (x_n)\}[/math]。
模糊集合与特征函数的关系
当论域 [math] U [/math] 为无限集时,[math] U [/math] 上的模糊集 [math] A = \int_{x \in U} \frac {\mu_A (x)}{x} dx [/math]
例如对于隶属函数[math]\mu_A = \begin{cases} 1, & 0 < x < 20 \\ \dfrac{40 – x}{20}, & 20 \leq x \leq 40 \\ 0, & 40 < x < 120 \end{cases}[/math],求其模糊集 [math] A [/math]得:
[math]A = \int_{x \in [0, 20]} \frac{1}{x} dx + \int_{x \in [20, 40]} \frac{\frac{40 – x}{20}}{x} dx + \int_{x \in [40, 120]} \frac{0}{x} dx[/math]
模糊集合的分类
| 极小型(年轻、小、冷) | 中间型(中年、中、暖) | 极大型(老年、大、热) |
|---|---|---|
| [math]\mu_A(x) = \begin{cases} 1, & x < a \\ \dfrac{b – x}{b – a}, & a \leq x \leq b \\ 0, & x > b \end{cases}[/math] | [math]\mu_A(x) = \begin{cases} 0, & x < a \\ \dfrac{x – a}{b – a}, & a \leq x < b \\ 1, & b \leq x < c \\ \dfrac{d – x}{d – c}, & c \leq x < d \\ 0, & x \geq d \end{cases}[/math] | [math]\mu_A(x) = \begin{cases} 0, & x < a \\ \dfrac{x – a}{b – a}, & a \leq x \leq b \\ 1, & x > b \end{cases}[/math] |
隶属函数的确定方法
F分布确定隶属函数
| 类型 | 极小型 | 中间型 | 极大型 |
|---|---|---|---|
| 矩阵型 | [math]\mu_A = \begin{cases} 1, & x \leq a \\ 0, & x > a \end{cases}[/math] | [math]\mu_A = \begin{cases} 1, & a \leq x \leq b \\ 0, & x < a \text{或} x > b \end{cases}[/math] | [math]\mu_A = \begin{cases} 1, & x \geq a \\ 0, & x < a \end{cases}[/math] |
| 梯形型 | [math]\mu_A = \begin{cases} 1, & x \leq a \\ \dfrac{b – x}{b – a}, & a \leq x \leq b \\ 0, & x > b \end{cases}[/math] | [math]\mu_A = \begin{cases} \dfrac{x – a}{b – a}, & a \leq x \leq b \\ 1, & b \leq x \leq c \\ \dfrac{d – x}{d – c}, & c \leq x \leq d \\ 0, & x < a, x \geq d \end{cases}[/math] | [math]\mu_A = \begin{cases} 0, & x < a \\ \dfrac{x - a}{b - a}, & a \leq x \leq b \\ 1, & x > b \end{cases}[/math] |
| k次抛物型 | [math]\mu_A = \begin{cases} 1, & x \leq a \\ \left( \dfrac{b – x}{b – a} \right)^k, & a \leq x \leq b \\ 0, & x > b \end{cases}[/math] | [math]\mu_A = \begin{cases} \left( \dfrac{x – a}{b – a} \right)^k, & a \leq x \leq b \\ 1, & b \leq x \leq c \\ \left( \dfrac{d – x}{d – c} \right)^k, & c \leq x \leq d \\ 0, & x < a, x \geq d \end{cases}[/math] | [math]\mu_A = \begin{cases} 0, & x < a \\ \left( \dfrac{x - a}{b - a} \right)^k, & a \leq x \leq b \\ 1, & x > b \end{cases}[/math] |
| Γ型 | [math]\mu_A = \begin{cases} 1, & x \leq a \\ e^{-k(x – a)}, & x > a \end{cases}[/math] | [math]\mu_A = \begin{cases} e^{k(x – a)}, & x < a \\ 1, & a \leq x \leq b \\ e^{-k(x - a)}, & x > b \end{cases}[/math] | [math]\mu_A = \begin{cases} 0, & x < a \\ 1 - e^{-k(x - a)}, & x \geq a \end{cases}[/math] |
| 正态型 | [math]\mu_A = \begin{cases} 1, & x \leq a \\ \exp\left\{ -\left( \dfrac{x – a}{\sigma} \right)^2 \right\}, & x > a \end{cases}[/math] | [math]\mu_A = \exp\left\{ -\left( \dfrac{x – a}{\sigma} \right)^2 \right\}[/math] | [math]\mu_A = \begin{cases} 0, & x \leq a \\ 1 – \exp\left\{ -\left( \dfrac{x – a}{\sigma} \right)^2 \right\}, & x > a \end{cases}[/math] |
| 柯西型 |
[math]\mu_A = \begin{cases} 1, & x \leq a \\ \dfrac{1}{1 + \alpha(x – a)^\beta}, & x > a \end{cases}[/math] [math](\alpha > 0, \beta > 0)[/math] |
[math]\mu_A = \dfrac{1}{1 + \alpha(x – a)^\beta}[/math] [math](\alpha > 0, \beta \text{为正偶数})[/math] |
[math]\mu_A = \begin{cases} 0, & x \leq a \\ \dfrac{1}{1 + \alpha(x – a)^{-\beta}}, & x > a \end{cases}[/math] [math](\alpha > 0, \beta > 0)[/math] |
模糊综合评价
模糊综合评价的定义
说法一:就是以模糊数学为基础,将一些边界不清、不易定量的因素定量化.
说法二:要把论域中的对象对应评语集中一个指定的评语.
说法三:将方案作为评语集并选择一个最优的方案.
- 评价指标集 (因素集):[math]U = \{u_1, u_2, \ldots, u_n\}[/math]
- 评价等级 (评语集):[math]V = \{v_1, v_2, \ldots, v_m\}[/math]
- 指标的权重 (权重集):[math]A = \{a_1, a_2, \ldots, a_n\}[/math]
例如,评价一件衣服的受市场欢迎程度,可以从 [math] U = \{\text {花色、样式、价格、耐用度、舒适度}\}[/math] 方面考虑,以此来判断这件衣服是 [math] V = \{\text {很欢迎、欢迎、一般、不欢迎}\}[/math],其中我们给 [math] U [/math] 中的因素赋予权重 [math] A = \{0.1, 0.2, 0.1, 0.4, 0.2\}[/math]
一级模糊综合评价
评语集带有评价色彩型
例 1. 在对企业员工进行考核时,由于考核的目的、考核对象、考核范围等的不同,考核的具体内容也会有所差别。有的考核涉及的指标较少,有些考核又包含了非常全面且丰富的内容,需要涉及很多指标。鉴于这种情况,企业可以根据需要,在指标个数较少的考核中,运用一级模糊综合评判,而在问题较为复杂、指标较多时,运用多层次模糊综合评判,以提高精度。
Step 1. 确定因素集
可从工作业绩、工作态度、沟通能力、政治表现方面构成评价指标体系集合,即因素集[math]U = \{u_1, u_2, \ldots, u_n\}[/math]
Step 2. 确定评语集
将评语分为好、较好、中等、差、很差,即构成评语集[math]V = \{v_1, v_2, \ldots, v_m\}[/math]
Step 3. 确定各因素的权重
也就是确定因素集的重要程度,即权重集 [math] A = {a_1, a_2, \ldots, a_n}[/math],其中,[math] a_i [/math] 为第 [math] i [/math] 个因素的权重,且满足 [math]\sum_{i = 1}^{n} a_i = 1 [/math]。对于权重的确定方法,如果题目没有给出数据则用层次分析法,如果给出了数据则用熵权法的TOPSiS,也可以不确定权重。
Step 4. 确定综合模糊判断矩阵
对指标 [math] u_i [/math] 来说,对各个评语的隶属度为评语集 [math] V [/math] 上的模糊子集。对指标 [math] u_i [/math] 的评判记作:[math] R_i = [r_{i1}, r_{i2}, \ldots, r_{im}][/math] ,其中 [math] r_{im}[/math] 表示指标 [math] u_i [/math] 对评语 [math] v_m [/math] 的隶属度。
各指标的综合模糊判断矩阵为:[math]R = \begin{bmatrix} r_{11} & r_{12} & \cdots & r_{1m} \\ r_{21} & r_{22} & \cdots & r_{2m} \\ \vdots & \vdots & \ddots & \vdots \\ r_{n1} & r_{n2} & \cdots & r_{nm} \end{bmatrix} = \begin{bmatrix} R_1 \\ R_2 \\ \cdots \\ R_n \end{bmatrix}[/math],其意义按行和列分别有不同的解释。
- 因素集 可从工作业绩、工作态度、沟通能力、政治表现方面构成评价指标体系集合,即因素集;
- 评语集 将评语分为好、较好、中等、差、很差,即构成评语集。
解题步骤
- 取因素集 [math] U = \{\text {政治表现} u_1, \text {工作能力} u_2, \text {工作态度} u_3, \text {工作成绩} u_4\}[/math]。
- 取评语集 [math] V = \{\text {优秀} v_1, \text {良好} v_2, \text {一般} v_3, \text {较差} v_4, \text {差} v_5\}[/math]。
- 确定各因素权重 [math] A = [0.25, 0.2, 0.25, 0.3][/math](层次 or 熵权法)
- 对每个因素 [math] u_i [/math] 做出评价(注:隶属度之和不一定为1,和隶属函数的选取有关)
- [math] u_1 [/math] 由群众评议打分确定:[math] R_1 = [0.1, 0.5, 0.4, 0, 0][/math],这个式子表示,有 10% 的人认为政治表现优秀,50% 的人认为政治表现良好,40% 的人认为政治表现一般,认为政治表现较差或差的人数为
- [math] u_2 [/math] 和 [math] u_3 [/math] 由部门领导打分确定:[math] R_2 = [0.2, 0.5, 0.2, 0.1, 0][/math],[math] R_3 = [0.2, 0.5, 0.3, 0, 0][/math]。
- [math] u_4 [/math] 由单位考核组成员打分确定:[math] R_4 = [0.2, 0.6, 0.2, 0, 0][/math]
- 将上述向量组合,即可构成模糊综合判断矩阵,[math]R = \begin{bmatrix} 0.1 & 0.5 & 0.4 & 0 & 0 \\ 0.2 & 0.5 & 0.2 & 0.1 & 0 \\ 0.2 & 0.5 & 0.3 & 0 & 0 \\ 0.2 & 0.6 & 0.2 & 0 & 0 \end{bmatrix}[/math]
- 进行模糊综合评判[math]B = A \cdot R = [0.25, 0.2, 0.25, 0.3] \cdot \begin{bmatrix} 0.1 & 0.5 & 0.4 & 0 & 0 \\ 0.2 & 0.5 & 0.2 & 0.1 & 0 \\ 0.2 & 0.5 & 0.3 & 0 & 0 \\ 0.2 & 0.6 & 0.2 & 0 & 0 \end{bmatrix} = [0.175, 0.53, 0.275, 0.02, 0][/math]取数值最大的评语作为最后综合评判结果,所以评判结果为“良好”.
评语不带有评价色彩型
例 2. 某露天煤矿有五个边坡设计方案,其各项参数根据分析计算结果得到边坡设计方案的参数如下:
| 项目 | 方案1 | 方案2 | 方案3 | 方案4 | 方案5 |
|---|---|---|---|---|---|
| 可采矿量/万吨 | 4700 | 6700 | 5900 | 8800 | 7600 |
| 基建投资/万元 | 5000 | 5500 | 5300 | 6800 | 6000 |
| 采矿成本 | 4.0 | 6.1 | 5.5 | 7.0 | 6.8 |
| 不稳定费用 | 30 | 50 | 40 | 200 | 160 |
据勘探,该矿探明储量 8800 吨,开采投资不超过 8000 万元,试做出各方案的优劣排序,选出最佳方案。
解题步骤
- 因素集 [math] U = \{\text {可采矿量} u_1, \text {基建投资} u_2, \text {采矿成本} u_3, \text {不稳定费用} u_4\}[/math]。
- 评语集 [math] V = \{\text {方案一} v_1, \text {方案二} v_2, \text {方案三} v_3, \text {方案四} v_4, \text {方案五} v_5\}[/math]。
- 用层次分析法或熵权法确定权重(不唯一) [math] A = (0.25, 0.2, 0.2, 0.1, 0.25)[/math]。
- 确定模糊综合判断矩阵
- 确定隶属函数,因为评语集不带有评价色彩(无法区分极大极小型),所以这里我们需要自行构造隶属函数。
- 根据常识可以知道,可采矿量为极大型,基建投资为极小型,采矿成本为极小型,不稳定费用为极小型。
- 因为表中勘探的地质储量最大为 8800 吨,故可采矿量的隶属函数 [math] u_A (x) = \frac {x}{8800}[/math]
- 投资约束是 8000 万元,所以 [math] u_B (x) = 1 – \frac {x}{8000}[/math]
- 根据专家意见,采矿成本 [math] a_1 \leq 5.5[/math]元/吨为低成本,[math] a_2 = 8.0 [/math]元/吨为高成本,故
[math]u_c(x) = \begin{cases} 1, & 0 \leq x \leq 5.5 \\ \dfrac{8.0 – x}{8.0 – 5.5}, & 5.5 \leq x \leq 8.0 \\ 0, & 8.0 < x \end{cases}[/math] - 不稳定费用的隶属函数 [math] u_D (x) = 1 – \frac {x}{200}[/math]
- 代入数据,得到模糊综合判断矩阵[math]R[/math]:
- 进行模糊综合评判:[math]B = A \cdot R = (0.7435, 0.5919, 0.6789, 0.3600, 0.3905)[/math]。由此可知,方案一最好。
| 项目 | 方案1 | 方案2 | 方案3 | 方案4 | 方案5 |
|---|---|---|---|---|---|
| 可采矿量 | 0.5341 | 0.7614 | 0.6405 | 1 | 0.8636 |
| 基建投资 | 0.3750 | 0.3125 | 0.3375 | 0.15 | 0.25 |
| 采矿成本 | 1 | 0.76 | 1 | 0.4 | 0.48 |
| 不稳定费用 | 1 | 0.4480 | 0.6552 | 0 | 0.0345 |
多级模糊综合评价
当因素集中指标过多时,会具有较高的相关性,我们可以将这些指标分类讨论,例如:
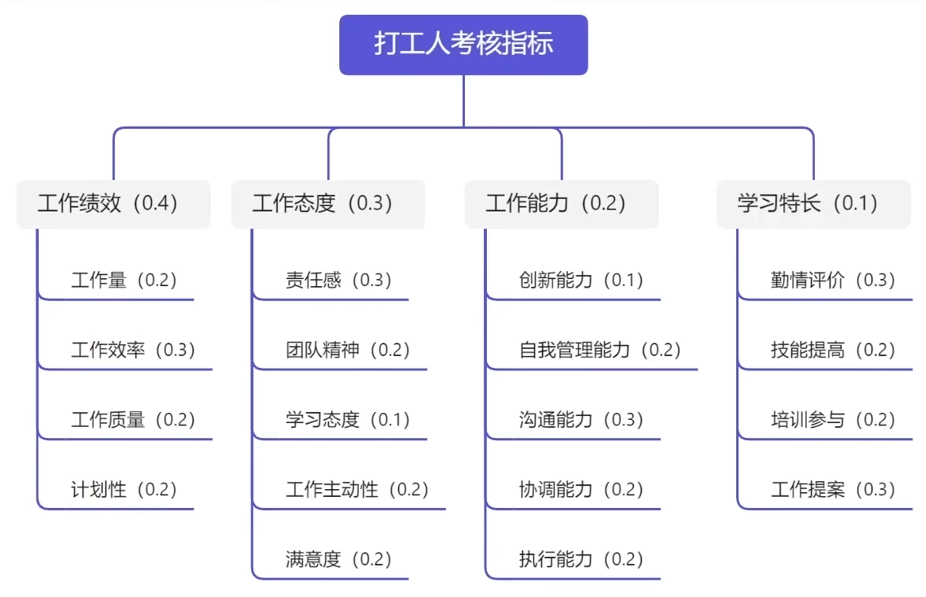
解题步骤
- 第一步:划分因素集
划分因素集 [math] U = \{u_1, u_2, \ldots, u_n\}[/math] 为若干组
[math] U_1 = \{u_1, u_2, \ldots, u_k\}[/math],且不同子集互不相同,相交为空。
即,[math] U = \bigcup_{i=1}^{k} U_i \ \text {且} \ U_i \bigcap U_j = \Phi \ (i \neq j)[/math] - 第二步:确定评语集与二级评判
确定评语集 [math] V = \{v_1, v_2, \ldots, v_m\}[/math],并对第二级因素集 [math] U_i = \{ u_1^{(i)}, u_2^{(i)}, \ldots, u_{n_i}^{(i)} \}[/math] 进行评判,得到综合判断矩阵[math]R_i = \begin{bmatrix}
r_{11}^{(i)} & r_{12}^{(i)} & \cdots & r_{1m}^{(i)} \\
r_{21}^{(i)} & r_{22}^{(i)} & \cdots & r_{2m}^{(i)} \\
\vdots & \vdots & \vdots & \vdots \\
r_{n_i 1}^{(i)} & r_{n_i 2}^{(i)} & \cdots & r_{n_i m}^{(i)}
\end{bmatrix}, \ (i = 1, 2, \ldots, k)[/math]
若 [math] U_i = \{ u_1^{(i)}, u_2^{(i)}, \ldots, u_{n_i}^{(i)} \}[/math] 的权重为 [math] A_i = \{ a_1^{(i)}, a_2^{(i)}, \ldots, a_{n_i}^{(i)} \}[/math],则二级综合评判[math]B_i = A_i \cdot R_i[/math](即 [math] U_i [/math] 对于评语集 [math] V [/math] 的隶属度 ) - 第三步:一级因素综合评判
对第一级因素 [math] U = \{U_1, U_2, \ldots, U_k\}[/math] 进行综合评判,若第一级权重为 [math] A = \{a_1, a_2, \ldots, a_k\}[/math],构造综合判断矩阵 [math] R = [B_1, B_2, \ldots, B_k]^{\text {T}}[/math],则一级综合评判:[math]B = A \cdot R[/math]。 - 第四步:按最大隶属度确定相关评语
实际上,上述过程就是对每组二级中的因素集做一次一级模糊综合评价,将其结果按行拼接成第一级的判断矩阵,再与第一级的权重做一次矩阵乘法,就是二级模糊评价的结果。
总结
用模糊综合评价的套路
- Step1:该方法用于解决评价类问题;
- Step2:确定因素集(如果因素过多可考虑用多级,可以用主成分分析法)确定各因素权重,注意每一级权重之和为 1;
- Step3:确定评语集(有无评价色彩);
- Step4:从最后一层开始逐级确定每级因素对评语集的隶属度(逐级打分);
- Step5:根据隶属度确定相关评语(最好画成直方图)