本文最后更新于481 天前,其中的信息可能已经过时,如有错误请发送邮件到1910452164@qq.com
假设训练集原始数据分布如下:
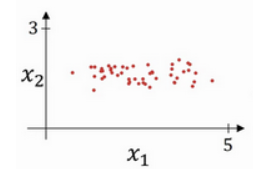
第一步:零均值化
[math]\mu=\frac{1}{m} \sum_{i=1}^{m} x^{(i)}[/math]
[math]x = x – \mu[/math]
即计算数据的均值,然后平移坐标系,另均值归零。
零均值化后,数据分布变为如下情况:
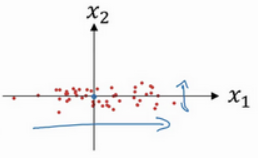
第二步:归一化方差
[math]x = x – \mu [/math]
[math]\sigma^{2}=\frac{1}{m} \sum_{i=1}^{m}\left(x^{(i)}\right)^{2}[/math]
将输入数据各维度的方差调整至均衡,方便后续的梯度下降。
方差归一化后,数据分布变为下图:
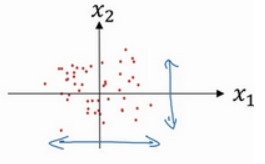
可以看到数据更加分散,并且两个维度的分布较均匀。
为什么要使用归一化?
首先需要回顾一下损失函数:[math]J(w,b)={\textstyle\frac{1}{m}}\sum_{i=1}^{m}L(\hat{y}^{(i)},y^{(i)})[/math]
如果使用非归一化的输入特征,代价函数会像下面的左图这样:
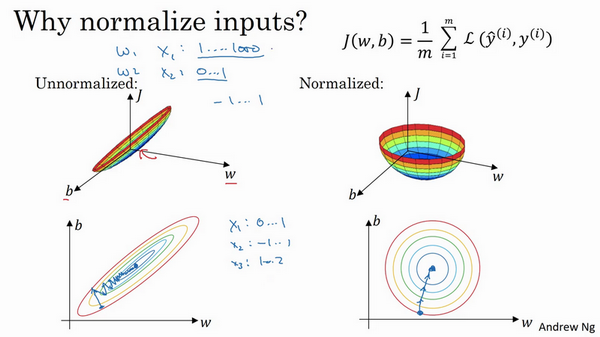
然而如果你归一化特征,损失函数将变为右图,平均起来看更对称。如果你在左图这样的代价函数上运行梯度下降法,你必须使用一个非常小的学习率。但如果函数是一个更圆的球形轮廓,那么不论从哪个位置开始,梯度下降法都能够更直接地找到最小值,你可以在梯度下降法中使用较大步长,而不需要像在左图中那样反复执行。